Why Crawl Budget is important?
We have conducted this entire guide on our own website for a live demonstration. Crawl budget report will help us to understand if we have some serious issues with any given website, let us take our own website for instance https://thatware.co. The purpose of the guide is to check whether the given website has better crawling and what else we can do for fixing the issues (if any persists). Meanwhile, the Crawl budget stands for the number of pages that a Google bot or a spider can crawl on any given day. It’s the number of webpages which a Google crawler can crawl on a particular day.
Today in this guide we will show you the live demonstration of the following:
- How to measure the crawl budget of your website
- How to identify if you have a crawl budget issue
- How to spot the crawling issues
- Recommendations on fixing the crawling issues
- The real-time demonstration’s on fixing the crawling issues
- The final results obtained and the benefits, now without further ado. Let’s start!

Current Observation’s:
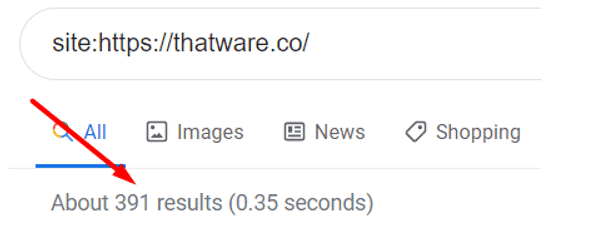
First of all, we need to check the index pages count for the website. The easiest way to do it is to use type Site:{your domain name} in the Google search bar. Google index value for thatware.co = 391 (Check the below screenshot for proof of statement)
Now, it’s time to check the daily crawl rate for the website. Perform the following steps to view the daily crawl stats.
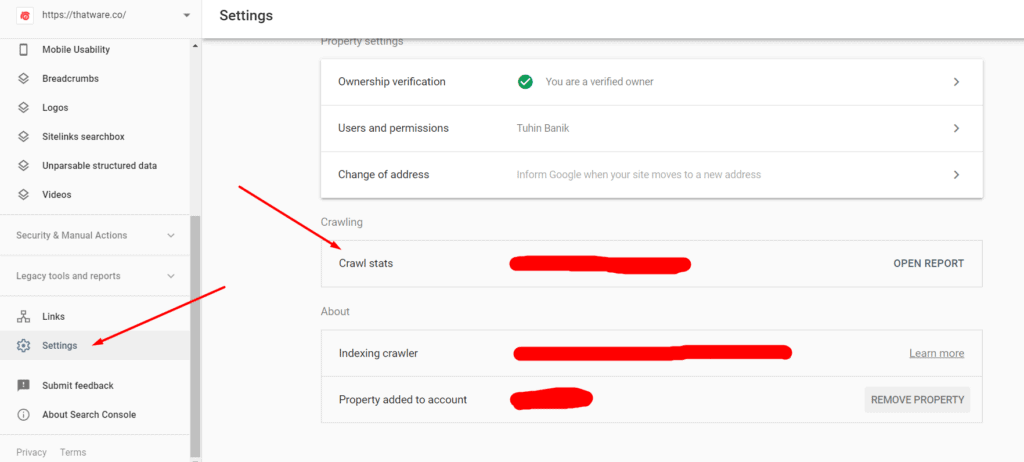
Step 1: Open Google search console
Step 2: Click on Property for the campaign
Step 3: Click on settings
Step 4: Click on “Crawl stats” (check the below screenshot)
Step 5: Now one can count the value by hovering the mouse over the preferred timeline.
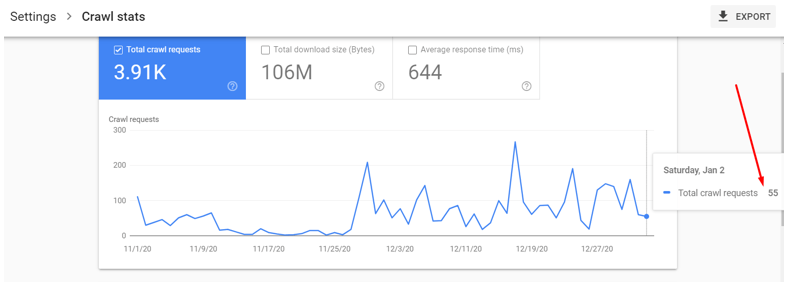
Hence, the daily crawl rate (real-time) for our website is 55 as shown on the above screenshot. Please note, for large websites preferably an eCommerce website one can take 7 days average value as well. Since our website is a service-based website hence we decided to take the real-time value.
Crawl Budget Calculation and ideal scores:
Crawl budget = (Site Index value) / (Single day crawl stat)
The ideal score are as follows:
- If the Crawl budget is between 1 – 3 = Good
- If the Crawl budget is 3 – 10 = Needs improvement
- If the crawl budget is 10+ = its worst and needs immediate technical fixes
Now coming back to our budget calculation, as per the formula stated above,
Crawl budget for thatware.co = 391 / 55 = 7.10
Now let us compare our Crawl Budget:
The score for thatware.co is 7.10 which is far more than the ideal zone of 1 – 3.
Summary
Hence, the website thatware.co is affected by the crawl budget. In other words, if our website contains 7000 pages (let’s consider); then it would take 7000/7 = 1000 days for completing a single crawling cycle. This would be a deadly situation for an SEO of a website since any changes to any webpages might take ages for Google to crawl and reflect the revised rankings in SERP.
The proposed solution for the rectification
In layman’s terms, the most effective way of fixing crawl budget issues is to make sure there are no crawling issues on the websites. These are the issues that will cause delay or error when Google spider will try to crawl the given website. We have identified several issues that might lead to crawl budget wastage and needs to be fixed with an immediate impact. The proposed solutions for our website are as under:
Chapter 1: Sitemap XML optimization
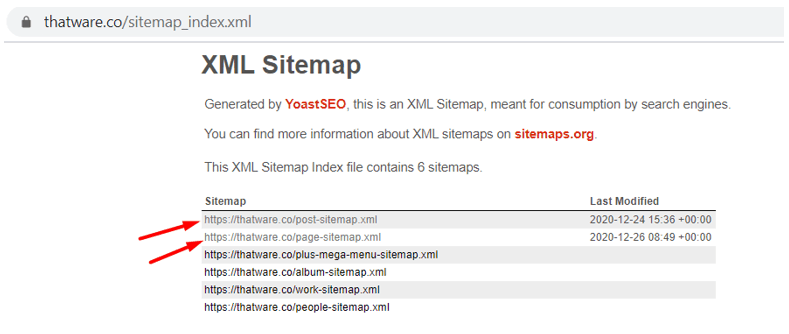
Check the above screenshot, our sitemap contains separate Post and pages sitemaps which are not optimized as per proper protocol orders. We suggest performing the below steps to make sure everything is fine:
Step 1: Make sure the XML sitemap contains the below hierarchy
{Should start with Homepage with priority set to 1.0 and change frequency value = Daily}
{Then it should be followed with Top navigation pages with priority set to 0.95 and change frequency value = Daily}
{Then it should be followed with top landing and service pages with priority set to 0.90 and change frequency value = Daily}
{Then it should be followed with Blog pages with priority set to 0.80 and change frequency value = Weekly}
{Then it should be followed with Miscellaneous pages with priority set to 0.70 and change frequency value = Monthly}
Step 2: After that, put the sitemap path in Robots.txt
Step 3: Also, declare the sitemap on search console as well
Chapter 2: Mobility Issues check-up
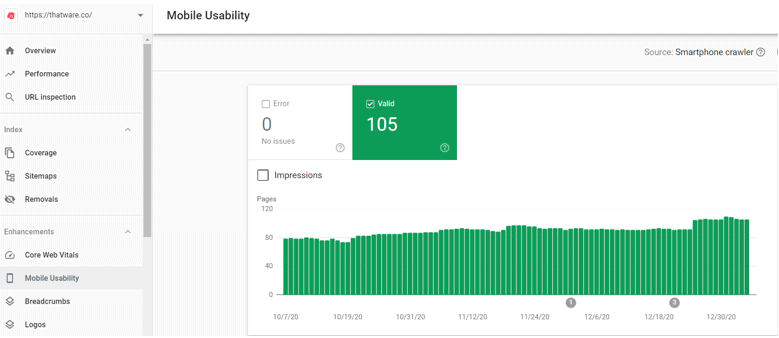
As per the above screenshot obtained from the Google search console, the Mobile usability we can see that we don’t have errors on mobile issues which is Good. But there is a negative point here,
Remember we had 391 pages indexed but the screenshot above shows that there are only 105 valid mobile pages. Hence, we can conclude that there is an issue with mobile-first indexing.
This issue can be solved, once the above sitemap has been optimized properly and then all live URL’s should be fetched manually via Google search Console. The steps are as under:
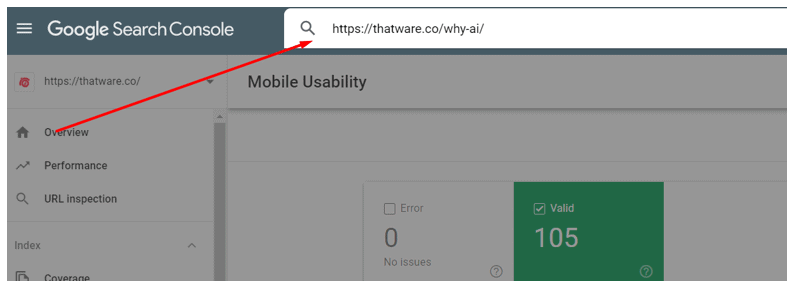
Step 1: Take the URL and paste on the bar as shown on the below screenshot and press enter
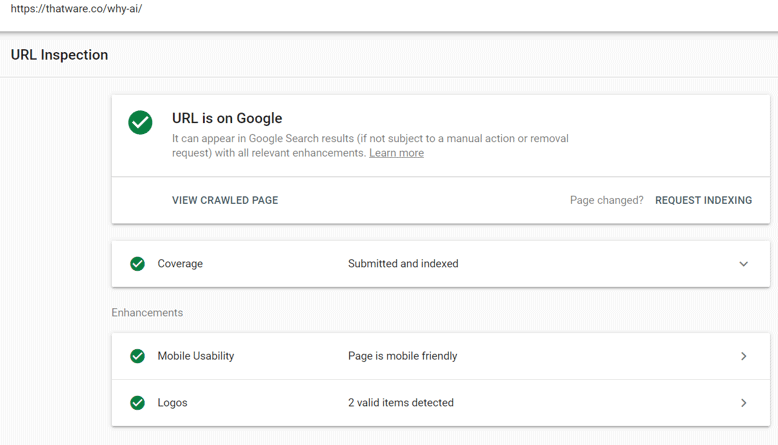
Step 2: Once you press enter you will see something like this as shown on the below screenshot. Make sure “Coverage” and “Mobile Usability” is ticked green. If not, then click them further to see the issues.
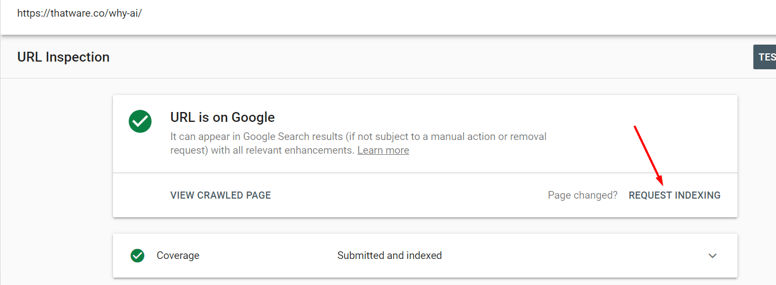
Step 3: Click on “Request Indexing” and then Google will take the latest index feed of your website within 48 hours max. This will solve the mobile issues once and for all.
Chapter 3: Coverage issues and Index Bloat check-up
Before going further, let us explain what Index bloat actually means. In layman term, index bloat means the index of random pages in Google which have almost no user value. These kinds of pages should be de-indexed or deleted from the website. A couple of common index bloat scenarios are as under:
1. 4XX errors
2. 5XX errors
3. Redirect chains
4. Removing unwanted pages from Google index via “removal tool”
5. Zombie pages needs to be de-indexed such as “Category pages”, “tag pages”, “author pages” etc
6. Incorrect Robots.txt
7. Excluded pages as seen from Google search console (check the screenshot below)
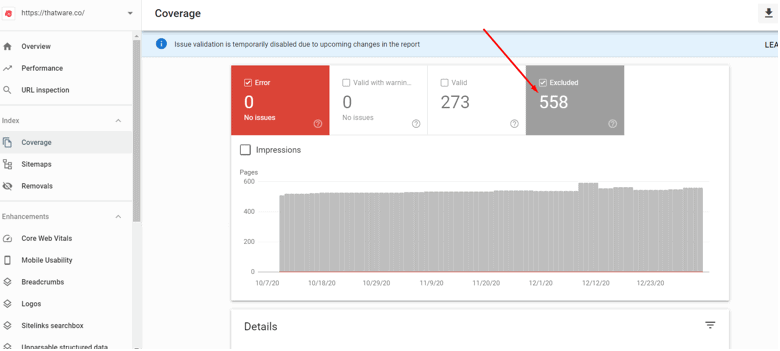
However, common technical findings based on chapter 3 for thatware.co are as under:
1. Index of unwanted pages such as /categories, /author
2. 4XX pages indexed as seen from Excluded in GSC
3. Improper index due to non-optimized Robots
4. Improper no-index distribution
Here’s what we actually did to fix the issues
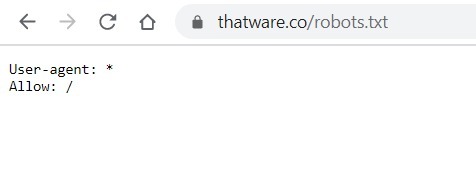
Case 1: Re-optimized Robots.txt
Our initial Robots.txt code is shown as under
After that, we have revised our robots.txt as shown under, you can view the full robot’s code by visiting here: https://thatware.co/robots.txt
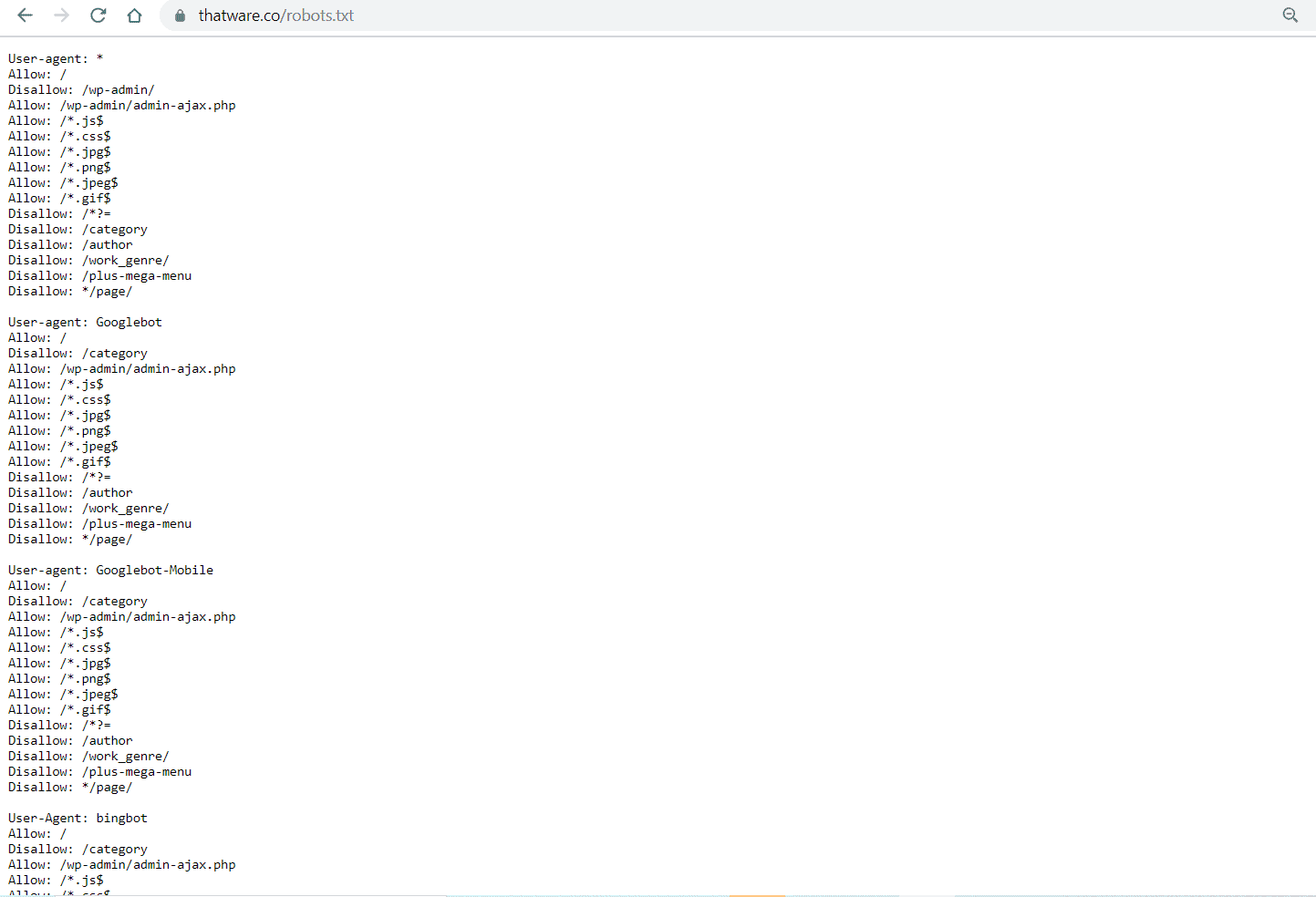
Did you get confused right? haha! Okay, let us explain what actually we have done to our robots.
- We have declared all the crawlers individually which we want our site to be indexed
- We have allowed all our assets such as .css, .js, .jpg, etc to be crawled by the crawlers.
- We have disallowed unwanted paths that might cause unnecessary index bloats such as category pages, author pages, paginated pages, and etc. Please note ” * ” before any path indicates that robots should crawl or de-crawl if something starts after the asterisk. And ” $ ” indicates that robots should crawl or de-crawl any path ending before the dollar sign.
- We have also disallowed automated search queried pages which would turn 404.
These all modifications have been done which will help with more enhanced crawling and better indexing of our website.
Case 2: Removal of unwanted pages
Removing unwanted indexed pages from Google will help to preserve the crawl budget. This will also help to eliminate index bloat. We have performed the following steps:
Step 1: We have once again used site:https://thatware.co on the Google search bar and manually checked all indexed results.
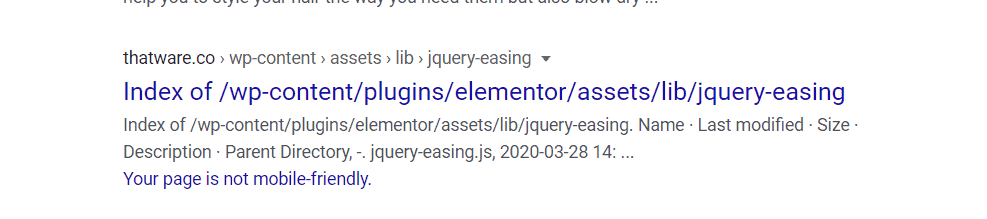
Step 2: We made a list of all unwanted results which we don’t want to be indexed. One example, as shown under. This is an example of URL’s which we definitely don’t want to be displayed and indexed.
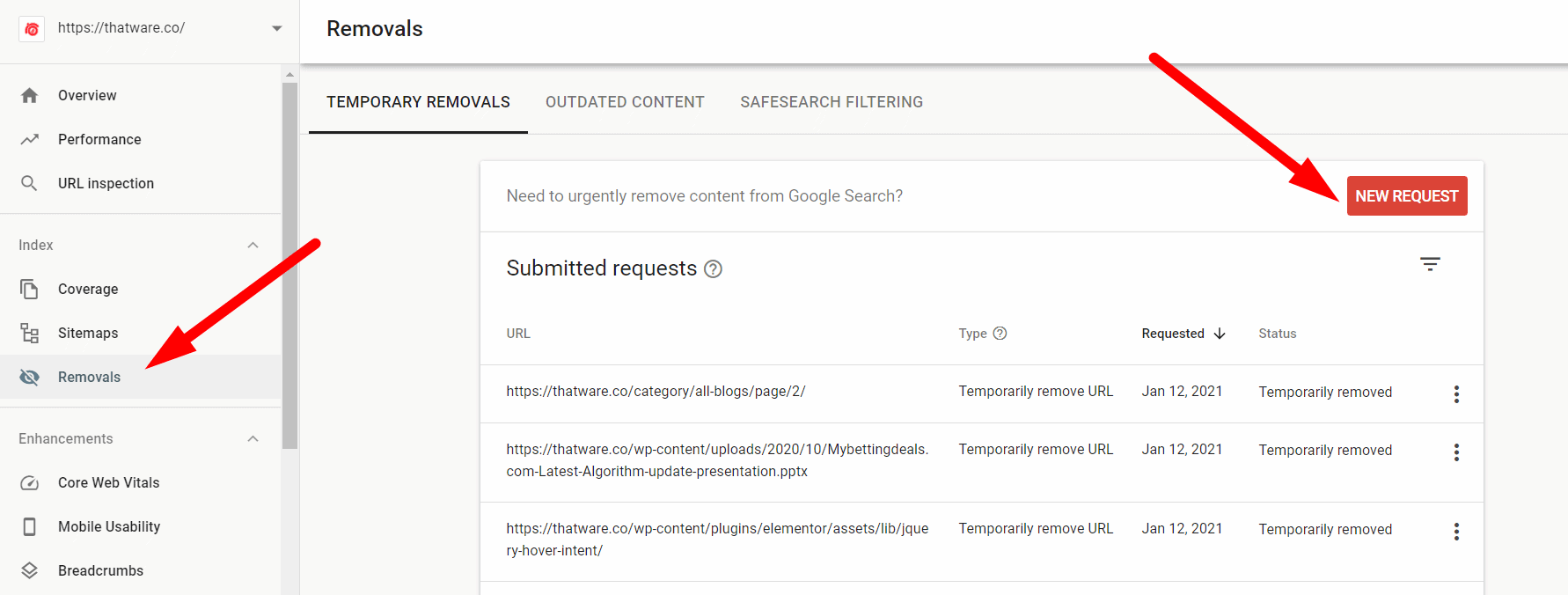
Step 3: Once, we got all the list of the URLs. Then we used the removal tool from the Google search console and have updated them on Google to be de-indexed from SERP. The process is shown in the screenshot below. Click on “Removals” from the search console and click on “New request”.
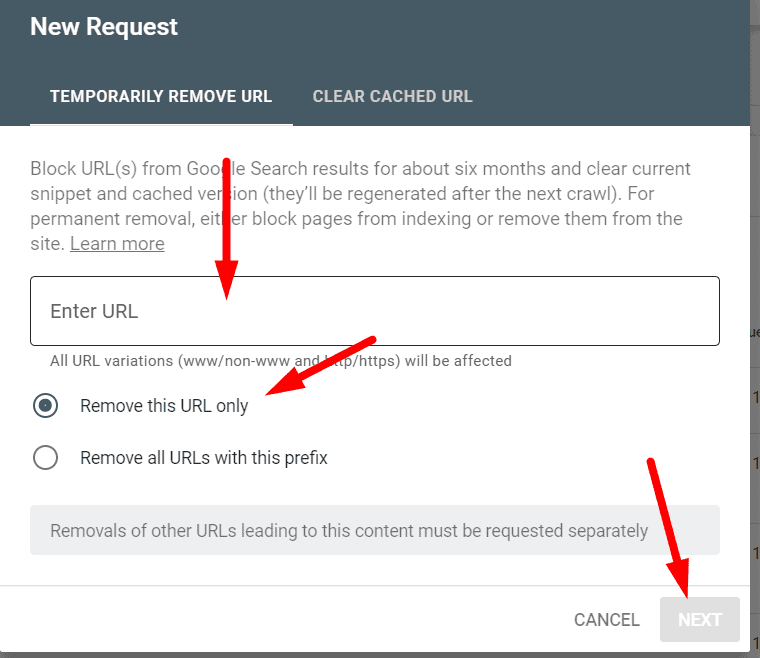
Step 4: Once you click on “new request” as stated in the previous step. Then you will get a message box as shown in the below screenshot. Just enter the URL which you want to de-index and click “next”. Job is done! make sure to choose option one only “remove this URL only” as shown in the screenshot under. Please note, the request needs approx 18 hours to be processed successfully.
Hence, unwanted URL removal can make the crawl budget wastage down and will improve the crawl ratio for the website. Since it reduces index bloat up-to a greater extent.
Case 3: Web Vitals Fixes
You can use GTmetrix to check your WEB Vitals. This is a tech portion and hence you can ask your developers to fix the Web Vitals scores. Some of the common fixes are as under:
- Make sure there are lesser round-trips
- Low DOM requests
- Server-side rendering
- JS optimization
- CSS optimization
- First-fold optimization, and much more. . .
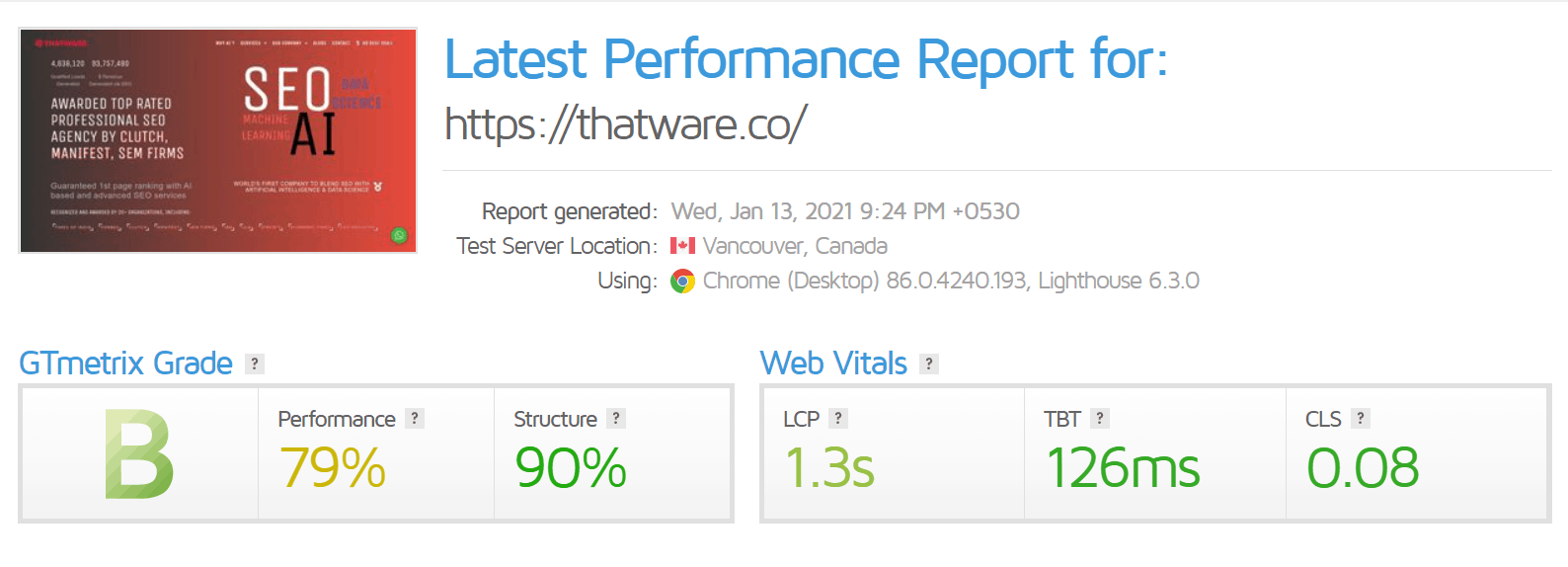
Our Web Vitals have been already fixed by our Dev team, the latest scores are as under (not that bad huh!):
Case 4: Taxonomy modification’s
In our case, we are using WordPress as our CMS. The purpose of this step is to ensure that our unwanted pages such as category pages, author pages, etc are disabled to appear on the search index. In other words, we are declaring meta robots no-follow and no-index on the unwanted pages. The steps are as under:
Step 1: Click Yoast SEO and go to “Search Appearance”. Check the below screenshot.
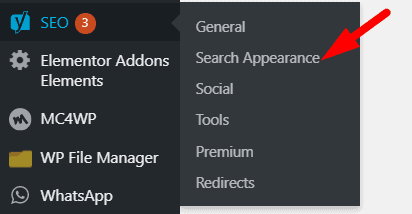
Step 2: Then click on”Taxonomies” as shown on the below screenshot and choose all option’s as “NO” which you don’t want to index on search engine result pages (SERP).
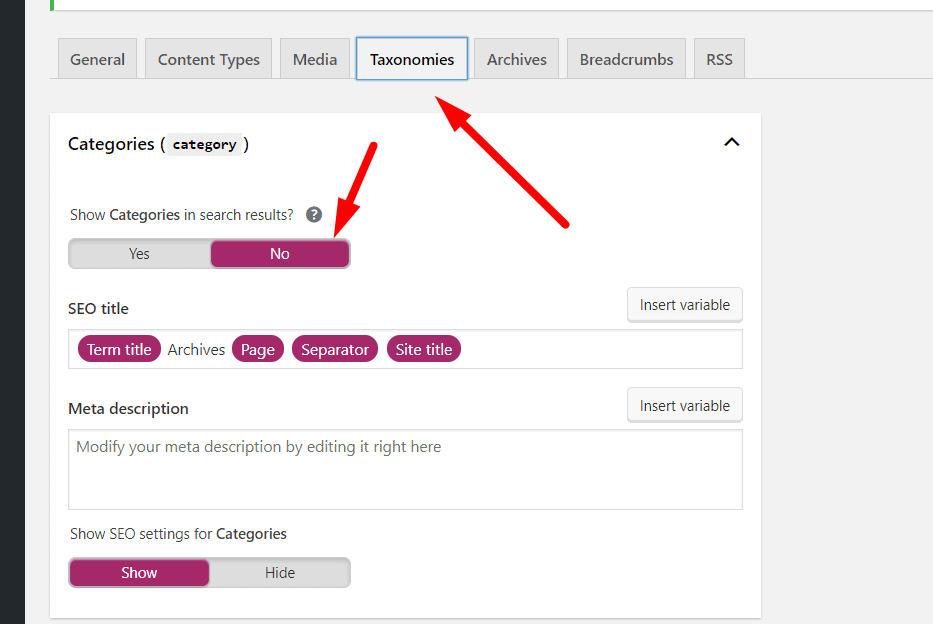
This step would prevent unwanted index of pages which normally provides no customer value or user experience. Now the thing is what you can do if you don’t have WordPress as your CMS? The answer is below:
Well, in case of a situation where your CMS is not WordPress then just paste the below code on <head> on the pages where you don’t want them to be indexed.

Case 5: Sitemap optimization
We have optimized our XML sitemap as under:
- We have used the proper hierarchy of the sitemap (as earlier explained above). In other words, we have assigned proper priority and frequency order based on the priority of the pages which we want to serve our audience like-wise.
- We have ensured no broken or unwanted URLs are there on our current XML
- We have also ensured there are no redirection’s or canonical issues on our current XML
- We have updated the latest sitemap on the Google search and also have ensured the Google search console triggered no possible errors or issues. Check the screenshot below for a better understanding. The screenshot will showcase that when we updated our XML sitemap in GSC, it had no errors and the status was ‘Successful’.
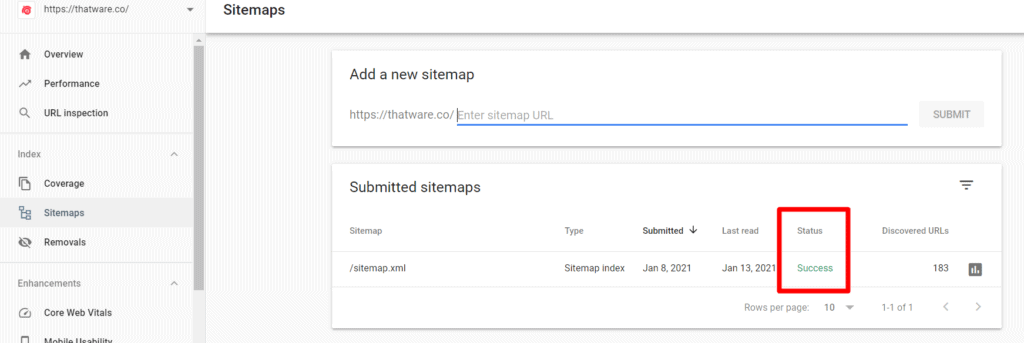
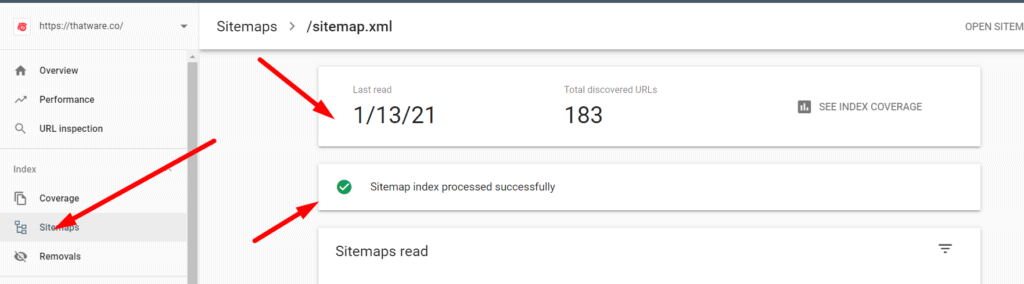
Conclusion
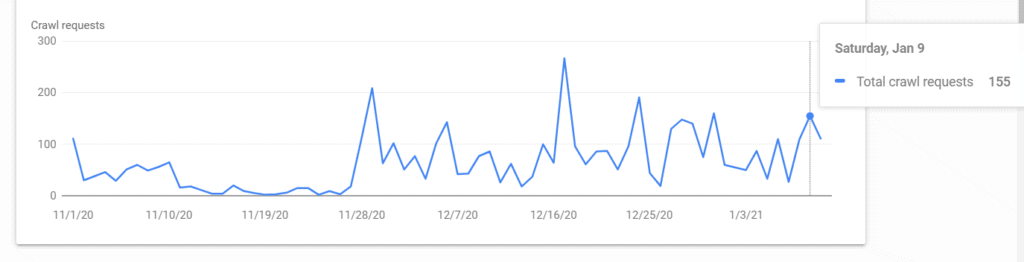
As a result of all our efforts, our latest daily crawl stats is 155, as shown in the screenshot below:
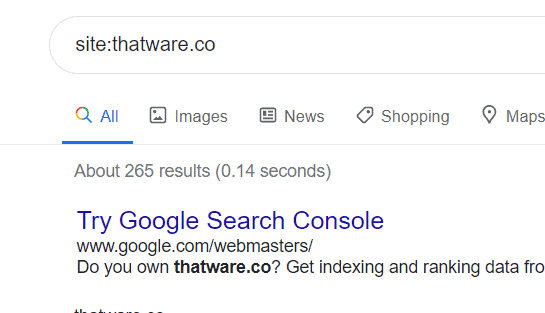
Latest index stats of our website is 265 as shown in the screenshot below:
Hence, the latest crawl budget of our website is 265/155 = 1.7, hence our crawl budget score is perfectly optimized.
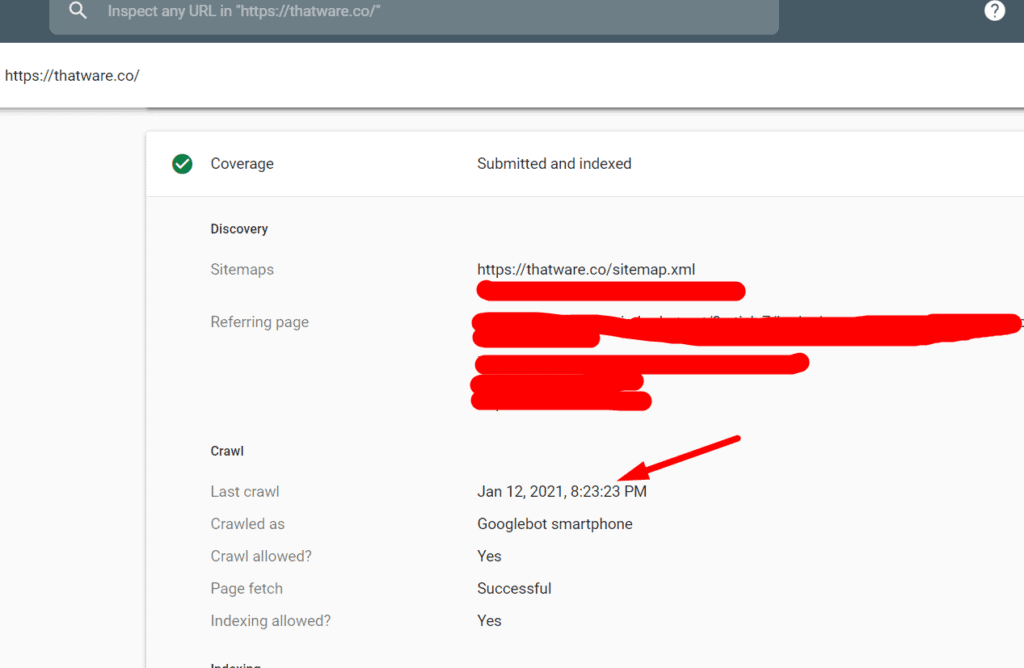
The finest benefit which we are enjoying right now due to a good crawl budget score is the frequent index of our webpages. Check the screenshot below, our website is getting crawled almost daily. This will help us in achieving more SEO benefits. We hope, this guide will also help you to solve your crawl budget statistics! Hope you loved the guide, do share!
You can read more about the on-page SEO definitive guide here: https://thatware.co/on-page-audit/
You can read more about Passage Indexing here: https://thatware.co/passage-indexing/
You can read more about Smith Algorithm here: https://thatware.co/smith-algorithm/

